Blog Posts
A Stable CandyStore
April 11, 2026
TL;DR Note: here is Part 1 and Part 2 CandyStore has reached v1.0 – the O(1) key-value store now has true crash consistency, a stable file format, and an overall simpler design. If you haven’t read the previous posts, CandyStore is a pure-Rust, embedded key-value store that relies on hash-based...
»»»

CandyStore: the Road to Consistency
September 06, 2024
We (Sweet Security) published a post on Reddit to tell the Rust community about CandyStore, our fast key-value store, and I feel there were some recurring themes that I did not address on the first post. I tried answering specific comments, but it’s clear there’s been some misunderstanding around the...
»»»

A Sweet Key-Value Store
August 22, 2024
TL;DR Note: here is Part 2 Sweet Security has just released CandyStore - a very fast Key-Value Store in Rust with negligible memory overhead and unique features like lists and queues. The library is meant to be used an embedded database, but in the future we may release a server...
»»»

Some Notes on 'D for the Win'
August 23, 2014
So it turns out my last post, D for the Win got all over the place. I published it late at night, went to bed, and when I got back in the morning all hell broke loose. And even more surprisingly, the vast majority of the reactions (at the ones...
»»»

D for the Win
August 21, 2014
I’m a convert! I’ve seen the light! By the way, be sure to read part 2 as well. You see, Python is nice and all and it excels in so many domains, but it was not crafted for the ever growing demands of the industry. Sure, you can build large-scale...
»»»

Construct Plus Plus
February 26, 2014
As you may already know, I’m a type-system junkie. My heart yearns for the strongly-typed languages of the world, but being a I’m a practical guy, I mostly work with Python. That said, I’ve been keeping myself busy trying to find a way write a statically-typed version of Construct. I...
»»»
Tales of a Stressed Kernel
July 27, 2013
Spending most of our time (as developers) in the high-level world, it’s easy to occasionally forget the true nature of our systems and how fragile they really are. Well, perhaps fragile is not the right word here, more like intricate or perhaps chaotic - you cannot fully predict the effect...
»»»

TTYs: Never gets boring
June 16, 2013
Just a short rant: I’m working on an interactive console used for debugging a computer cluster. It connects to all nodes in the cluster and provides you with a single place to run queries. It uses the new (not yet officially-released) zero-deploy feature of RPyC, which sets up a secure,...
»»»

Academia
June 06, 2013
I thought it’d be useful to publish some of the seminars/technical papers that I worked on when studying at Tel Aviv University, instead of letting them rot in a drawer. Hope you find it useful/interesting. Chierchia: On Plurality of Mass Nouns A technical report on Gennaro Chierchia’s paper, Plurality of...
»»»

Cartesian Tree-Product
May 02, 2013
I have to admit that my day-to-day life involves very little algorithmic problems, but here and there I get a chance to think. In this post, I’d like to discuss an interesting problem that I’ve met several times already in my programming career, each time in different settings. When I...
»»»
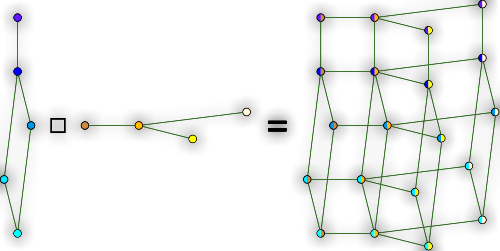
A Survey of Construct 3
January 07, 2013
I’m working on Construct 3 again and I’m exploring lots of new ideas. I wanted to share these ideas at this early stage to get feedback on them from users, to keep the project on track. This survey starts a bit slow (as I’m not counting on users being familiar...
»»»
New Experiences
December 15, 2012
Okay, I’ve been slacking off and I feel I’ve got some explaining to do… Allow me to start by admitting that I lied. If you remember, I said I wanted an easy life, but then the opportunity came and I knew I had to take it: I’ve joined two friends...
»»»

Loads of Plumbum
October 26, 2012
It’s kind of funny how things turn out. I haven’t done any work on Plumbum almost since it was released, back in May, and all of the sudden everything’s happening at fast pace. So version 1.0 was released earlier this month, followed by 1.0.1, which has added support for PuTTY...
»»»
Plumbum Hits v1.0
October 06, 2012
After 5 months in the oven, I’ve finally released Plumbum v1.0,
which brings forth a host of bug-fixes, improvements and new features.
If you’re new to Plumbum, please refer to the
introductory blog post.
Cheers.
»»»
Hypertext: In-Python Haml
October 03, 2012
TL;DR: Just show me the code I recently got back to web development for some venture I’m working on, which reminded me just how lousy the state of the art is. There’s no nice way to put it: we’re doing web development all wrong. It’s not an anecdotal thing I...
»»»

I, for one, welcome our Singularity overlord
September 22, 2012
I’m finding myself pondering quite a lot lately over the upcoming Singularity (in its Kurzweilesque sense). I think I’ve first heard of the concept two or three years ago, at a Science on the Bar event, and while it did seem thought-provoking, I simply dismissed the idea. I’d guess it...
»»»

New Beginnings
September 01, 2012
This is a time of change in my life. September marks the last month of me being a student at Tel Aviv University, a position I’ve greatly enjoyed (and hated) for the past three years. I still have a couple of projects to hand in, but the finish line has...
»»»

Splitbrain Python
August 14, 2012
I was working together with a colleague on a complex distributed test-automation solution on top of RPyC, and we looked for a way to make our existing codebase RPyC-friendly (without altering it). The design of the test framework called for a master machine and several slave machines, such that tests...
»»»

ReHelloWorld
August 06, 2012
Tada! The new design is here. The previous one was based on some Drupal theme I once used (before moving to github pages) that I tried to mimic when I barely new CSS. Over the past eight months it just grew, patch by patch, until it became an inconsistent conglomerate....
»»»

Javaism, Exceptions, and Logging: Part 2
July 09, 2012
Considering the reactions to the previous post in this series, my intent was obviously misunderstood. Please allow me to clarify that I was not attacking Java or Python: Java is popular and has proven to be productive, both as a language and as an ecosystem; the stylistic and semantic choices...
»»»

Javaism, Exceptions, and Logging: Part 1
July 03, 2012
I’m working nowadays on refactoring a large Python codebase at my workplace, and I wanted to share some of my insights over two some aspects of large-scale projects: exceptions, logging, and a bit on coding style. Due to it’s length, I decided to split it over three installments; the first...
»»»

RPCs, Life and All
June 25, 2012
A colleague of mine, Gavrie Philipson, has written an interesting blog post titled Why I Don’t Like RPC, in which he explains that transparent/seamless RPCs (a la RPyC) make debugging and reasoning efforts hard. For instance, you might work with an object (a proxy) that points to an object on...
»»»

Reed-Solomon Codec
June 08, 2012
Some Background I’m working on an image processing project for the university, whose purpose is to embed (an extract) a print-scan resilient watermark into an image. This project has (sadly) gotten me acquainted with Matlab, from which I quickly ran way into the friendlier realms of Scipy and friends (Skimage...
»»»

Some Notes on RPyC 3.2.x
June 06, 2012
As I said in the previous blog post, I hoped for v3.2.2 to be the last release of the 3.2 line… Naturally, I was wrong :) Turns out the fix for issue #76 was buggy, and I decided to finally remove the use of excepthooks in favor of taking care...
»»»
RPyC 3.2.2 Released
June 01, 2012
This is a maintenance release, fixing some issues concerning introspection, ForkingServer and signals, IronPython and signals, and SSH on Windows. It also introduces optional logging of exceptions that occur over the RPyC connection to the server’s logger (or any other logger instance, given in the connection’s configuration). The change log...
»»»
The Future of Construct
May 16, 2012
It’s been a long while since I’ve put time into Construct. I gave up on it somewhere in 2007, right after the release of v2.0… I think I just got bored, and felt like the library was complete and extensible enough to survive on its own. Of course I was...
»»»
Introducing Plumbum - Shell Combinators
May 12, 2012
It’s been a while since I last blogged… sorry! Had a midterm exam, a seminar project to deliver (an O(n^3) parser for Tree Insertion Grammar), the routine family festivities of Passover, and this new thing, Plumbum, that has been keeping my mind overclocked while I should have been studying for...
»»»
Solving Systems of Linear Equations
March 25, 2012
Yet another university-related post, but I really enjoyed it so I thought I’d share: for a GUI- workshop I’m taking, we are given GUI-layout constraints as a system of linear equations, which we need to satisfy. To make life more interesting, some constraints are constant while some are parametric. There’s...
»»»

Easy Syntax for Representing Trees
March 07, 2012
I’m working on a parser for Tree Adjoining Grammar (TAG) for this seminar I’m taking. TAG is an extension of context-free grammar (CFG) that’s more powerful while still being polynomially-parsable. Anyhow, TAG makes use of “tree production rules” instead of the “linear” production rules of CFG: instead of S ->...
»»»

RPyC 3.2.1 Released
March 04, 2012
This is a maintenance release, fixing some minor bugs and resolving some issues with Python 3 compatibility. More on the change log. Python 2.x: it’s advisable to upgrade to this version. Python 3.x: it’s highly recommended to upgrade to this version, as it resolves some core issues that went under...
»»»
Toying with Context Managers
February 27, 2012
As I promised in the code-generation using context managers post, I wanted to review some more, rather surprising, examples where context managers prove handy. So we all know we can use context managers for resource life-time management: before entering the with-suite we allocate (open) the resource, and when we leave...
»»»

Wizard Dialog Toolkit
February 11, 2012
Following my Deducible UI post, and following some of the criticism it had received, I’d like to share something I’ve been working on (read: experimenting with) at my work place. You see, we have some “interactive wizards” that storage admins use to connect storage arrays to their hosts (say, a...
»»»

Just Got Me These
February 09, 2012
Hurrah! I just got me these: After the CS secretariat refused to let take math courses as electives (thus forcing me into taking boring stuff like SQL), I think Dover books and I are going to become good friends. It’s not like I have plenty of time to read them,...
»»»
Code Generation using Context Managers
January 31, 2012
When I was working on Agnos, a cross-language RPC framework, I had a lot of code-generation to do in a variety of languages (Python, Java, C#, and C++). At the early stages, I just appended strings to a list. It was quick and dirty, and it’s got the job done…...
»»»

Deducible UI
January 27, 2012
A Brief History I like automating things. I don’t like having to reiterate myself: my dream is to always be able to add only the necessary amount of information in order to make something possible. This is one reason, for instance, why I hate expressions like ArrayList<String> x = new...
»»»
Regarding Infix Operators
January 25, 2012
I got some reactions to the Infix Operators post, and wanted to point out some things. First of all, I’m not the one who came up with it – it’s a recipe from the Python Cookbook that’s been posted in 2005. I’m not taking credit for it or anything, I...
»»»

All Systems are Go
January 23, 2012
At last, I finished migrating the old drupal site to github pages. Everything is now fully revisioned and statically-generated (using Disqus for comments). Jekyll is so cool! I wrote all the HTML and forged the stylesheets myself… hope you like it. Anyhow, I’m happy with the design now, and I’ll...
»»»

Infix Operators in Python
January 22, 2012
As you may already know, there are 3 kinds of operators calling-notations: prefix (+ 3 5), infix (3 + 5), and postfix (3 5 +). Prefix (as well as postfix) operators are used in languages like LISP/Scheme, and have the nice property of not requiring parenthesis — there’s only one...
»»»

RPyC Moves to a New Site
August 29, 2011
RPyC is in the process of migrating from http://rpyc.wikidot.com to it’s new (and hopefully final) location at http://rpyc.sourceforge.net. Wikidot had served us well, and was easy to maintain, but they started displaying way to many ads and didn’t support rsync or SSH access, which meant I couldn’t upload the generated...
»»»
Learning Me a Haskell
August 17, 2011
Phew! Finally the semester’s over (just submitted my last project), and it’s time to clean up my ever-so-long backlog. Here goes nothing: I’ll start by posting something here, after this long while of neglect. As I’m sure you already know, I’m a long-time Pythonista, and I’m confident enough in calling...
»»»

Hooking Imports for Fun and Profit
June 17, 2011
I really love Python… it’s so hackable that it just calls for hacking, inspiring your imagination to find ways to stretch its boundaries. This time I decided to investigate into import hooks, to add some missing functionality I wanted to have. As you probably know, Python uses a flat namespace...
»»»
Python is Messy
May 07, 2011
A couple of days ago, Rudiger, a user of RPyC found a rather surprising bug, that in turn revealed just how gruesome python’s inner workings are. Rudiger was working with two machines, one 32 bit and the other 64 bit, and one machine had a netref to a remote list....
»»»
Content published under
